



排序规则包含一组用于字符串比较的特定于语言的规则,例如字母大小写和重音标记。对于由字母数字字符组成的简单项,一般的排序可适用,但是一旦包含特殊字符,例如 @、#、$、%(等)和 è、é、ê、ö(等等),你必须指定自己的排序规则。
MongoDB 在版本 3.4 中添加了排序规则支持,因此你可以为集合、视图、索引或支持排序规则的某些操作(如 find() 和 aggregate())指定排序规则。
今天的文章将简要介绍排序规则的概念,涵盖 MongoDB 中控制排序规则的字段,以及如何使用 Navicat for MongoDB GUI 管理和开发工具在 MongoDB 中指定排序规则。此外,我们今天将详细介绍排序规则文档的前三个字段,其余部分将在第 2 部分中介绍。
排序规则文档字段
若要使用默认选项以外的排序规则选项,你可以指定一个排序规则文档。它由以下字段组成:
{locale: <string>,
caseLevel: <boolean>,
caseFirst: <string>,
strength: <int>,
numericOrdering: <boolean>,
alternate: <string>,
maxVariable: <string>,
backwards: <boolean>
}
你可以在“排序规则”选项卡上看到 Navicat 中显示的相同字段:
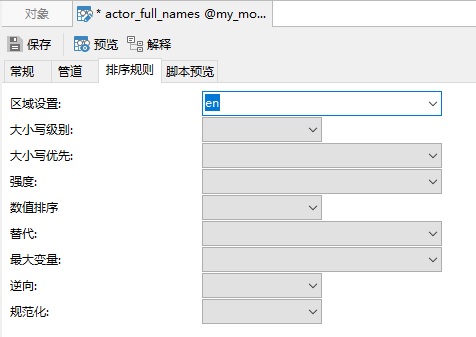
在以上所有字段中,只有“区域设置”字段是必需的,所有其他排序规则字段都是可选的。
现在让我们仔细看看每个字段,并好好地了解每个字段允许的值:
-
区域设置(locale):
区域设置标识特定用户社区,即一组共享相似文化和语言习语的个体。在实践中,社区是所有说同一种语言并生活在同一个国家的人的交集。例如,法国的法语区域与加拿大的法语区域不同。因此,“fr”是法国法语的区域设置代码,而“fr_CA”是添加了加拿大的2个字符国家/地区代码。虽然这两个地区有许多相似之处,但亦有一些差异,例如货币,法国使用欧元(€),而加拿大使用美元($)。
正如你想象的那样,有许多区域设置代码。“区域设置”下拉列表包含许多更常见的代码。列表中的第一项“simple”指定了简单的二进制比较。你也可以在下拉列表的文本框输入你想要的代码。
语言之间的排序差异
关于排序,每种语言都有自己的排序顺序,有时甚至是多个排序顺序。以下是在不同的区域设置下对相同名称进行排序:
- English (en): bailey, boffey, böhm, brown
- German (de_DE): bailey, boffey, böhm, brown
- German phonebook (de-DE_phonebook): bailey, böhm, boffey, brown
- Swedish (sv_SE): bailey, boffey, brown, böhm
-
大小写级别(caseLevel):
这个标志用于确定是否包含大小写比较。
- 如果是“on”,则包括大小写比较。
- 如果是“off”,则不包括大小写比较。
-
大小写优先(caseFirst):
这个字段用于确定大小写差异的排序顺序。有效值包括:
- “upper”:大写字母排序在小写之前。
- “lower”:小写字母排序在大写之前。
- “off”:默认值。类似于“lower”,但略有不同。
总结
在今天的文章中,我们了解了排序规则的概念,涵盖了 MongoDB 中控制排序规则的字段,并学习了如何使用 Navicat for MongoDB 在 MongoDB 中指定排序规则。熟悉了前三个排序规则字段的知识后,我们将在第 2 部分继续讨论最后五个字段。








