



顾名思义,关系数据库(RDBMS)维护表之间的关系,以有意义的方式组织数据。像 MongoDB 这样的文档数据库有时被称为“无结构”(schemaless),因为它们并没有像 RDBMS 那样真正实施关系。但是,虽然文档数据库不需要与关系数据库相同的预定义结构,但这并不意味着它们不支持。实际上,MongoDB 允许通过嵌入式和引用式方法对文档之间的关系进行建模。在今天的文章中,我们将使用Navicat for MongoDB尝试每一种方法。
测试用例
例如,我们将研究 ACME 公司的用例。他们需要以将雇员与地址联系起来的方式存储地址。一名雇员可以拥有多个地址,这使其成为一对多(1:N)关系。这没问题,因为 MongoDB 中的关系可以是一对一(1:1)、一对多(1:N)、多对一(N:1)或多对多(N:N),就像在关系数据库中一样。
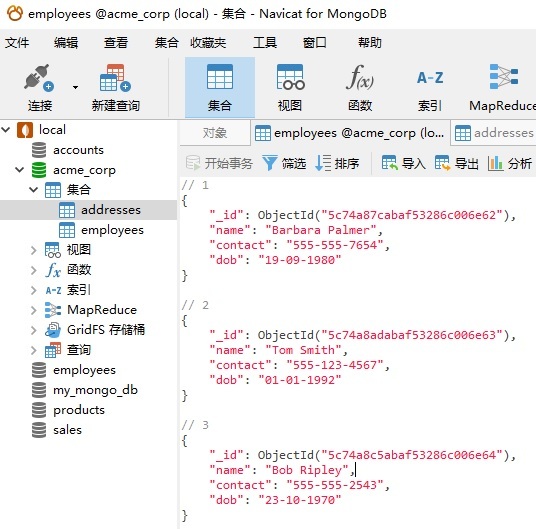
以下是 Navicat JSON 视图中 employees 文档的文档结构:
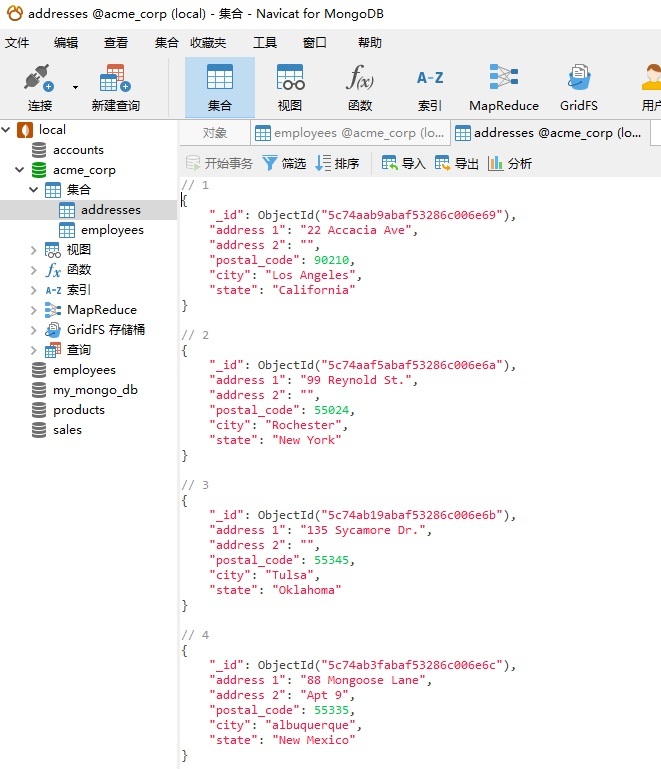
以下是 addresses 文档:
创建嵌入式关系
使用嵌入式方法,我们将 addresses 文档直接嵌入到 employees 文档中。我们可以在 Navicat for MongoDB 中轻松完成,如下所示:
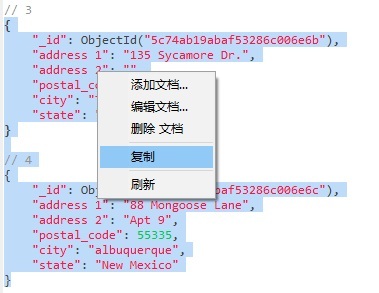
- 使用 JSON 视图打开 addresses 集合并复制最后两个文档:
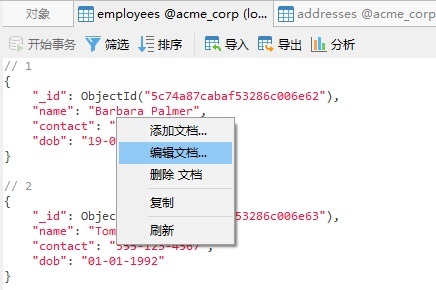
- 切换到 employees 集合并编辑第一个文档:
- 将地址粘贴到与其关联的雇员文档中,并将它们包含在“address”数组元素中:
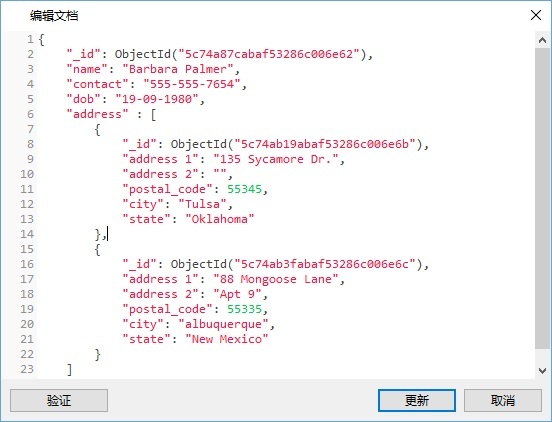
优点和缺点
此方法将所有相关数据保存在单个文档中,这使得检索和维护变得容易。现在可以在单个查询中检索整个文档:
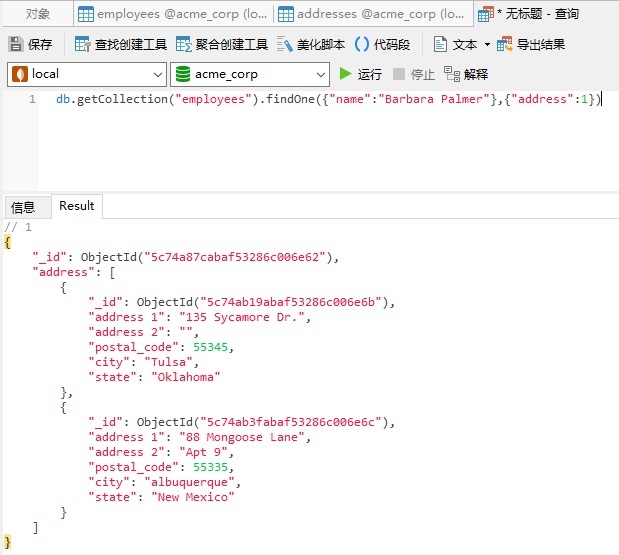
嵌入式关系的缺点是,如果嵌入式文档的大小不断增长,则会对读写性能产生负面影响。
创建引用式关系
使用此方法,雇员和地址文档都将保持独立,但雇员文档会有一个字段引用地址文档的 id 字段:
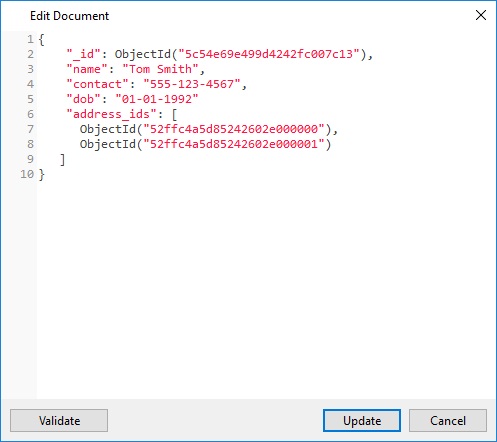
如上所示,雇员文档包含数组字段“address_ids”,其中包含相应地址的ObjectIds。 使用这些 ObjectIds,我们可以查询地址文档并从那里获取地址的详细信息。
优点和缺点
虽然这种方法可以使文档大小更易于管理,但我们现在需要两个查询来获取地址详细信息:一个用于从 employees 文档中检索 address_ids 字段,另一个用于从 addresses 集合中获取地址:
var result = db.employees.findOne({"name":"Tom Smith"},{"address_ids":1})
var addresses = db.addresses.find({"_id":{"$in":result["address_ids"]}})
预告
在下一篇文章中,我们将学习如何在 Navicat for MongoDB 中使用 MongoDB 引用式关系(也称为手动引用)和 DBRefs。你可以在产品页面了解有关它的更多信息。更可下载功能齐全的应用程序,并在 14 天的试用期内免费使用!








